I recommend it, a good book. The last three chapters include various standard phrases, which adds practical value to the book.
Presentations, Demos and Training Sessions. A guide to Professional English (Adrian Wallwork)
I recommend it, a good book. The last three chapters include various standard phrases, which adds practical value to the book.
Presentations, Demos and Training Sessions. A guide to Professional English (Adrian Wallwork)
Looks serious. It’s claimed there’s a protocol issue, and either client devices or access points need to be patched. If two unpatched devices come into contact, all the traffic becomes transparent for analysis, including https. A Mitm-type attack due to protocol imperfections. They promise to present it at a conference on November 1st, the article is already available
Let’s see if it’s as bad as the authors claim.
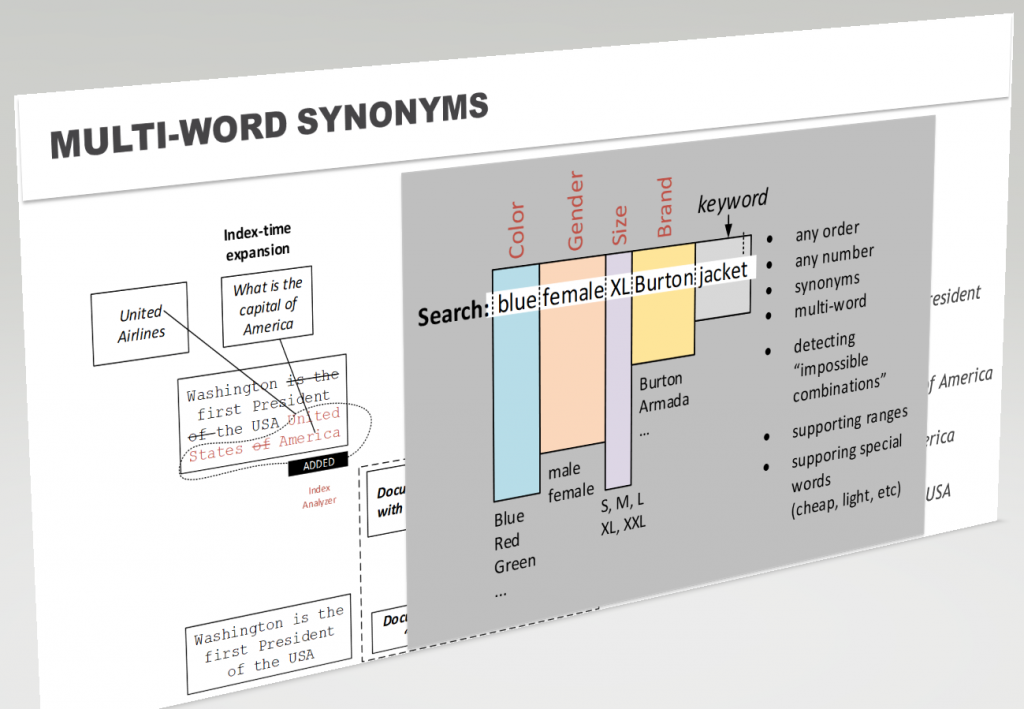
The third and fourth parts of my presentation at SAP Moscow. Last time it was about search analytics, this time it’s about phrase synonyms and automatic facet identification based on search queries. A pair of videos, 10 minutes each,
Welcome to all those interested.
Videos in Russian and English. The English version includes voiceover + subtitles.
Music Memos for iOS – an amazing thing! You play a tune, and it automatically adds accompaniment, guitar and drums, identifying the chords and tempo on the fly. I quickly played “Summertime,” and here’s what happened. Highly recommend!
Shelves from Barnes & Noble near the house. A stand about Russia








You surely know that nowadays, under the threat of hefty fines, websites are obliged to warn about the collection of info, cookies, etc. Some do this with a standard disclaimer, “We collect some data here, if you don’t trust us, please leave the site”. But on the website
, I saw how the right products for this purpose operate – TrustArc Cookie Consent Manager. It displays all services and allows selectively turning them on and off. The list turns out rather large, but also intriguing. It’s fascinating how many services large sites use to better sell products and to better know and track us.
Quite a list, huh?
Acxiom (acxiomapac.com)
Adobe Marketing Cloud – Advertising Services (everesttech.net)
Amazon Ad System (amazon-adsystem.com)
Connexity, Inc. (connexity.net)
Delego Software Inc. (sap-isp-public.delego-cloud.com)
Google Inc. (storage.googleapis.com)
Microsoft Advertising (bat.bing.com, bing.com, c.bing.com)
OnAudience.com (onaudience.com)
Outbrain (outbrain.com)
SAP SuccessFactors Inc (rmk-map-12.jobs2web.com)
The Church of Jesus Christ of Latter-day Saints (eaexplorer.hana.ondemand.com)
Visual IQ (myvisualiq.net)
Walmart (beacon.walmart.com)
Wayfair (wayfair.com)
YaaS (profile.yaas.io)
AdGear Technologies, Inc. (adgrx.com)
Adbrain (adbrn.com)
Adelphic Mobile (ipredictive.com)
Adform (adform.net)
Adition Technologies AG (adfarm1.adition.com)
AdotMob (adotmob.com)
AudienceOne (impact-ad.jp)
AudienceScience, Inc. (revsci.net)
Beeswax (bidr.io)
Bidtellect (bttrack.com)
BrightRoll, Inc. (btrll.com, geo-um.btrll.com)
Cardlytics (cardlytics.com)
Centro DSP (sitescout.com)
Conversant (dotomi.com)
Digital Advertising Consortium Inc. (y.one.impact-ad.jp)
Fluct (adingo.jp)
Geniee (gssprt.jp)
GetIntent (adhigh.net)
InfoLinks (infolinks.com)
Jivox (jivox.com)
Lifestreet (lfstmedia.com)
Ligatus (ligadx.com)
LinkedIn (px.ads.linkedin.com)
LiveIntent, Inc. (i.liadm.com, liadm.com)
Media Innovation Group (MIG) (ibeu2.mookie1.com, mookie1.com)
MediaMath (mathtag.com)
Nativo (postrelease.com)
OpenX (openx.net)
OwnerIQ (owneriq.net)
PulsePoint (contextweb.com)
RadiumOne (gwallet.com)
RhythmOne (formerly Burst Media) (1rx.io)
Rockerbox (getrockerbox.com)
Rocket Fuel (formerly [x + 1]) ru4.com
ScaleOut (socdm.com)
Sharethrough (sharethrough.com)
Simpli.fi Holdings (simpli.fi)
Skimlinks (skimresources.com)
Smaato (smaato.net)
Smart AdServer (smartadserver.com)
Smartclip (sxp.smartclip.net)
SpotXchange (spotxchange.com)
Switch Concepts (delivery.swid.switchadhub.com, switchadhub.com)
Taboola (taboola.com)
Teads.tv (teads.tv)
TellApart, Inc. (tellapart.com)
TripleLift (3lift.com)
Turn Inc. (turn.com)
Twitter (cdn.syndication.twimg.com)
erne.co, omnitagjs.com, s3xified.com
Yahoo (yahoo.com)
Zemanta (zemanta.com)
engage:BDR (ebdr3.com)
i-Behavior (global.ib-ibi.com)
sovrn (formerly Lijit Networks) (lijit.com)

In this headline absolutely everything
Tonight I made good progress in data mining & machine learning. I recommend Weka to everyone interested in the subject. It’s a math library with console tools, around which there is also a convenient graphical UI.
As a training exercise, I took 5000 products with 1800 characteristics from eBay (which is only 0.25% of their database), and clustered them based on characteristics alone. The outcome was separating items like cases separately, laptops separately. New products are correctly identified into the right group, hooray.
I also played with Time series forecasting. I uploaded search queries by day over the last couple of weeks. Weka provides estimates on the number of queries for the coming days. Cool, useful. For outliers beyond the original range, some sort of notifications could be devised, indicating a significant rise or fall.
There’s a database of 550,000 records from an online store (order number, product number, price, user number, date, time). I’m still not quite sure how to extract new knowledge from these through machine learning algorithms. Everything that comes to mind seems to be doable without much complexity. Any ideas?
(TIL) In my spare time from work, I watch Lavrenko’s lectures. This morning, I listened to the lecture “Laws of the Text”.
For example, did you know that there’s something called Zipf’s Law, stating that the frequency of the n-th word in the list of most common words of any language is roughly inversely proportional to its rank n?
Or here’s the empirical Benford’s Law: in number tables based on data from real-life sources (anything from electricity bills to house numbers in cities) the digit 1 appears at the beginning much more often than all the others (approximately in 30% of cases), the digit 2 appears more often than, for instance, 8 and so forth. Simply put, Benford’s Law can be described thus: there are always more small things in the world than large ones. The explanation for Benford’s Law lies in the fact that quantities in this world tend to grow exponentially, not linearly. Very intriguing.
Or take Heaps’ Law. The number of unique words in any text with N words follows the pattern f(N) = k*N^b, where b is most often equal to 1/2.
These laws allow, for example, to check data or a text for “naturalness”.
Or another example. For any very rare word, the probability that it will occur in a text is very low, which makes sense. But if this word does appear in the text, the likelihood of it appearing again is very high.